Inline Implementierung von Methoden
Statt eine Methode in der Klassendeklaration nur zu deklarieren(als Prototyp), kann man sie an dieser
Stelle ebensogut implementieren. Dazu lässt man das Semikolon nach dem (Element-)Funktions-
kopf einfach weg, fährt fort mit geschweifte Klammer auf und sagt der Methode, was sie tun soll.
Das sieht etwa so aus:
class FightClub{
private:
string tyler;
string marla;
public:
void BeatEmUp() //Jetzt kommts!
{
tyler=tyler+marla; //Das ist eine Inline Implementierung
cout < < tyler < < endl;
}
FightClub(); //Konstruktor
~FightClub(); //Destruktor
};
Auf diese Weise kann man sich zwar einerseits die Implementierung der Methode(Memberfunktion) außerhalb der
Klasse sparen, was sich auch gerade für kleinere Programme oft empfiehlt, andererseits entsteht die
Tendenz, das Modularitätsprinzip zu unterlaufen.
Der Punkt ist nämlich der:
Angenommen, meine inline implementierte Methode erweist sich z.B. ab Version 5.2 meiner Software
als für den weiteren Gebrauch unzulänglich - ich muss also etwas ändern - das hat nun in der Klassendeklaration
zu geschehen! Weiterhin angenommen, wir haben alle anderen Methoden gleichmäßig auf Programmierer
unserer eigenen Firma verteilt, während wir die Klassendeklaration aber im Extremfall von außen,
bzw. von einer anderen Softwarefirma erhalten haben - fertig kompiliert - wir können da gar nichts
dran verändern. So ein Ärger!! BeatEmUp( ); geht auf einmal nicht mehr!
Zugegeben das Beispiel ist übertrieben - trotzdem, zu diesem Zweck gibt es die Philosophie
der Objektorientierung, in der eben gerade die Modularität eines Programms eine große Rolle spielt.
Methoden der Klasse string
#include < string.h > ist eine Makropräprozessordirektive zur Einbindung einer Header - Datei,
während #include < string > eine Makropräprozessordirektive zur Einbindung einer Klasse ist.
Das bedeutet zugleich:
string.h enthält die Deklarationen von Funktionen, die wir nach der Einbindung verwenden können,
während die Einbindung von string als Klasse die objektbasierte Programmierung mit den Methoden
einer Standardklasse ermöglicht !
Sobald wir also
string bob;
oder string bob="Robert Paulsen";
sagen, haben wir nicht nur eine Variable bob vom Typ string erschaffen,
nein, wir haben auch eine Instanz bob vom Typ der Klasse string erschaffen.
Das hat folgende Konsequenzen :
Das Objekt bob besitzt sämtliche Methoden der Klasse string.
Wir können mit bob.length die Länge des Initialisierungsstrings ermitteln. Die Methode
length gibt einen Integer zurück, das wäre hier 14 - entsprechend den 14 Buchstaben + Leerzeichen
in "Robert Paulsen". Der String ist zwar wegen "\0" 15 Zeichen lang, length gibt aber trotzdem 14
zurück, um uns Denkarbeit zu sparen.
Mit bob.replace können wir nun den String ersetzen.
Dabei ist zunächst zu bedenken, welche Parameter die Methode replace braucht:
replace braucht einen Anfang des zu ersetzenden Strings, Anzahl der zu ersetzenden Buchstaben
und einen String, mit dem ersetzt werden soll. Letzterer ist in seiner Länge frei, d.h. nicht an
die Anzahl der zu ersetzenden Buchstaben gebunden !
Um den Anfang zu finden, benutzen wir die Methode find.
Daraus ergibt sich folgende Konsequenz:
bob.replace(bob.find("Robert"), 6, "fat man");
cout < < bob < < endl;
ergibt
fat man Paulsen , andererseits ergibt
bob.replace(bob.find("Robert"), 14, "fat man");
cout < < bob < < endl;
nur
fat man
.
(incipit Exkurs ternärer Operator)
verstanden ? gut : schlecht ;
Der ternäre(bedingte) Operator ist keine if - Entscheidung !
Er gibt nur Daten = Inhalte = Eigenschaften zurück. Das bedeutet hier :
"hast dus verstanden?" "ja" -----> "gut".
"hast dus verstanden?" "nein" -----> "schlecht".
Um sagen zu können: "Wenn du's verstanden hast, lies weiter, sonst nicht!", muss ich schon
eine if - Entscheidung bemühen:
if(bool verstanden= =true){
cout<<"lies weiter!";
}
else{
exit(-1); /*wobei man nicht vergessen sollte, um die Fkt exit nutzen zu können,
} die Header-Datei ctype.h, bzw, die Klasse cctype einzubinden !*/
(explicit Exkurs ternärer Operator)
Weiterhin stehen uns für die Instanz bob die Methoden erase, insert,
append und viele andere zur Verfügung.
Zur ausführlichen Information verweise ich auf die MSDN Hilfedateien in Visual C++.
Im Wesentlichen machen diese Funktionen das, worauf ihr Name hinweist.
getline hat gegenüber cin(einem Objekt, bzw. einer Methode der Klasse istream) den Vorteil
auch strings mit Leerzeichen einzulesen. cin macht am Ende eines Wortes halt.
Andererseits benutzt getline cin :
Syntax : getline(cin , name_der_variablen_wohin_getline_die_tastatureingabe_speichert);
Strings werden mit einem + Zeichen miteinander verkettet (konkateniert, concatenated).
Auch der Operator += funktioniert hier:
Schreibe ich also
bob += ", fight club member";
cout < < bob;
so erhalte ich als Ausgabe: "fat man, fight club member"
bob.erase(5, 4);
cout < < bob;
ergibt dann
"fat fight club member"
Wenn ich als weitere Instanz string bob1="but eager"; deklariert und initialisiert habe
und dann schreibe:
bob.insert(4, bob1, 0, 9); , erhalte ich von cout "fat but eager fight club member",
wobei die abschließende 9 die Anzahl der BUCHSTABEN, die eingefügt werden bezeichnet.
Wies aussieht ist die 0 die Anzahl der zu ersetzenden Zeichen.
Die Methode append, Bsp. bob.append("irgendwas"); hängt an den gespeicherten String
was auch immer an.
Wer jemals die Funktionen des Standard - Unix Editors Vi verwendet hat, dem wird nun
auffallen, dass diese den Methoden der Klasse String genau entsprechen !
Ratet mal, welchen Film ich heute morgen geguckt habe!
:)
Zu Kontrollstrukturen
a) Schleifen
Wegen großer interner Übereinstimmungen sind for - Schleifen geradezu prädestiniert dazu,
Arrays(Felder) zu befüllen oder auszulesen.
So hat ihr typischerweise ganzzahliger Zähler meistens den Initialisierungswert 0,
was dann dem ersten Element eines Feldes entspricht u.V.m..
For - Schleifen können grundsätzlich auch mit Gleitkommazahlen gezählt werden:
for(double b=0.0; b<12.8; b+=0.96)...........ALLES GEHT!!!
Mit Hilfe des sehr rangniedrigen Kommaoperators können for - Schleifen auch ganz andere
Formen als diese Standardform annehmen:
for(int i=0; i<10; i++)......
In C++ darf man innerhalb des for - Schleifenkopfes initialisieren, was in C nicht erlaubt war.
Andere Formen wären also:
for(int i=0, int j=3; i>15; i- -)..........
Wenn das so ist, dachte ich mir in meiner Standardrolle als Peter Schlauberger, müßte es ja
auch möglich sein, zwei geschachtelte for - Schleifen in eine zu packen, aber ach(!) :
#include < iostream >
using namespace std;
void main( )
{
int neu_array[10][10];
for (int i=0; i<10; i++)
{
for (int j=0; j<10; j++)
{
neu_ARRAYIJ=i*j;
cout << neu_array[i][j] <<"\t";
}
}
}
/*Dieselbe Geschichte kann leider nicht durch:
for(int i=0, j=0; i<10, j<10; i++, j++)......gelöst werden!!*/
Eine for( ; Ausdruck ; ).....Schleife arbeitet genau wie eine while - Schleife!
Die while - Schleife nimmt nur einen Ausdruck entgegen, nämlich die Abbruchbedingung.
Bsp.: while(x<10)....
Die Initialisierung des Zählers(i=0) setzt man normalerweise direkt über den Schleifenkopf.
Das In- bzw. Dekrement(++i) kommt dann in den Schleifenkörper. Grundsätzlich lassen sich for - Schleifen
durch while - Schleifen ersetzen und umgekehrt.
Eine for( ; ; ).....Schleife ist endlos.
Die entsprechende while - Schleife wäre while(true)....Was man da nimmt ist Geschmackssache.
Beide, die for - und die while - Schleife sind kopfgesteuert und haben darunter einen Schleifenkörper,
der, sofern er mehr als eine Anweisung enthält in geschweiften Klammmern stehen muss!
Die do{.......}while(....); - Schleife ist fussgesteuert durch den Ausdruck(Bedingung) in den runden Klammern hinter while.
Man nimmt sie besonders dann, wenn eine Anweisung am Anfang mindestens einmal ausgeführt werden soll, egal ob
die Bedingung zutrifft oder nicht.
Durch falsche Logik kann es gerade bei while - Schleifen auch dazu kommen, dass eine Schleife niemals ausgeführt wird!
Schleifen lassen sich beliebig ineinander verschachteln.
b) Entscheidungen
Eine if - Verzweigung gibt generell einen bool - Wert zurück. Ihre logische Struktur ist immer
Wenn das wahr ist, dann.......
Wenn z.B.: b= =12 ist, oder a>0 usw.
Wenn das also wahr ist, geschieht etwas, wenn nicht, dann geschieht gar nichts.
Zur if - Entscheidung gibt es auch einen optionalen else - Zweig, den man braucht, sobald
man will, dass auch wenn die Entscheidungsbedingung der if - Anweisung einen falschen Wahrheitswert
zurückgibt, trotzdem etwas geschieht.
Der else - Zweig fängt also den negativen Fall ab.
Man kann if - Entscheidungen beliebig ineinander verschachteln. Besser zur tieferen Verschachtelung eignen sich
jedoch else - if Ketten. Ihre Struktur ist wie folgt:
if(das&das= =wahr){....};
else if(wasAndres= =wahr){.....};
else if....usw., am Schluss steht normalerweise nochmal ein else - Zweig.
else(immernochnichtwahr= =true){explode -xxx now} //Ihr wisst schon, was ich meine!
Bei verschachteleten if - Verzweigungen ist es oft schwer zu erkennen, auf welches if sich
nun das else bezieht. Bsp.:
if(a<=33)
{
++a;
if(a<=22)
{
a+=12;
}
else
{
drop_pants( );
}
}
Der else - Zweig würde sich hier, trotz unübersichtliche Schreibweise auf die innere
if - Verzweigung beziehen, da sie immer erst nach der geschlossenen geschweiften Klammer der vorherigen
if - Abfrage beginnt ==> das ist übrigens noch ein Argument dafür, geschweifte Klammern auch bei
einzelnen Anweisungen zu benutzen, obwohl sie nur für eine Sequenz wirklich vorgeschrieben sind!
Aber wir haben auch noch unser allseits geliebtes case - Konstrukt :
Es beginnt mit switch gefolgt von einer Variablen, integer oder character, Selektor genannt,
die nun auf Konstanten verweist, die jeder Einzelanweisung(jedem case)vorangehen.
Hinter dem Selektor geht die geschweifte Klammer auf. Dann folgt der erste case, der für den Fall, dass er vom
Selektor ausgewählt hat, hier seine Anweisungen in beliebiger Zahl - ohne eine weitere geschweifte Klammer -
bereithält, sowie ein break(hier muss mindestens ein break; stehen), das dafür sorgt, dass der case(zu deutsch: "Fall")
nicht als Sequenz missverstanden wird, gefolgt gleich vom nächsten case usw., bis der Programmierer den
zwar optionalen, aber sehr empfehlenswerten default - Zweig eingibt, mit dem man üblicherweise
Falscheingaben abfängt.
int selektor;........................................
switch(selektor){
case 1: ergebnis = a % b; break;
case 2: ergebnis = a * b; break;
case 3: ergebnis = a + b; break;
case 4: ........ usw.
default: cout < < "Die unsinnigste Eingabe seit letztes Jahr Weihnachten!!!";
}
Mehr zur Objektorientierung
Die 4 Standardmethoden einer Klasse
1) Konstruktor
2) Destruktor
3) Der Kopierkonstruktor
4) Zuweisung
Beispiel für den Kopierkonstruktor
class X; //muss natürlich auch irgendwo implementiert sein!
X myX; //Ich instanziere ein Objekt 'myX' von der Klasse 'X'.
X myX2(myX); /*Nun schaffe ich noch ein Objekt vom Typ X, nämlich
myX2 und gebe dem Konstruktor als Anfangswert das Objekt
myX, das vom Typ der selben Klasse ist.*/
Der Pfeiloperator und andere Operatoren zu Zeigern und Klassen
Zum Aufruf einer Methode oder eines Datenelements einer Klasse bedient man sich des Punktoperators ( " . " ),
außerdem gibt es noch den Sternoperator ( " * " ), der in Körpern von Funktionen auch "Dereferenzierungsoperator" genannt wird.
Dieser heißt so, weil er - wenn man ihn vor den Namen eines Zeigers schreibt - dafür sorgt, dass der Zeiger den Inhalt dessen,
worauf er zeigt zurückgibt, statt seinen eigenen Inhalt(nämlich die Hexadezimale Adresse der Variablen, auf die er zeigt).
Weil man keine Referenz(die Adresse), sondern einen Inhalt zurückbekommt, spricht man von Dereferenzierung. Derselbe Operator
wird auch "Inhaltsoperator" genannt.
Der Pfeiloperator ( " - > " ), vereinigt Punkt- und Sternoperator, so dass folgende beide Ausdrücke synonym sind:
ZO - > DEObj
(* ZO) . DEObj
wobei ZO ein Zeiger auf ein Objekt ist und DEObj ein Datenelement eines Objekts.
Auf die gleiche Art kann man auch Methoden aufrufen.
Eine große Bedeutung in der OO hat ebenfalls der Scope - Resolution Operator(doppelter Doppelpunkt).
Man braucht ihn an vielen Stellen, z.B., wenn eine Methode außerhalb ihrer Klasse implementiert wird.
z.B.: KlasseDings: :Methode1( )
{ cout <<"irgendwas"; }
Call by Reference - Call by Value
Es gibt zwei verschiedene Arten, mit Datenelementen oder Variablen zu arbeiten:
1) - Übergabe der Inhalte als Wert (Value)
2) - Übergabe der Werte als Verknüpfung (Reference)
zu 1) Wird ein Wert als Parameter an eine Funktion übergeben, so wird der Wert grundsätzlich in die Funktion kopiert.
Das nennt man "call by value". Wenn der Wert daraufhin in der Funktion verändert wird, so unterscheidet sich
der Inhalt der Variablen in der Funktion dann von dem Inhalt der ursprünglich übergebenen Variablen.
Call by value hat den Vorteil, dass mir der Ausgangswert grundsätzlich noch immer zur Verfügung steht.
Bsp.:
void Fkt1(int i);
zu 2) Wenn eine Funktion einen Parameter erhält, der mit Ampersand (" & ") gekennzeichnet ist, so bedeutet
dies eine Referenz, bzw. einen Aliasnamen. Dieser Alias Name ist eigentlich nichts weiter als ein anderer
Bezeichner für ein und dieselbe Variable, die auch - wenn sie verändert wird - genau an der Speicherstelle,
an der sie auch vor Eintritt in die Funktion gestanden hat, verändert wird.
Bsp.:
void Fkt2(int &ri);
Auch ein Zeiger als Parameter ermöglicht einen call by reference. Der Unterschied zwischen einem Zeiger und
einer Referenz als Aliasnamen ist der, dass der Zeiger die Adresse des Datenbehälters enthält, auf den er
verweist, während die Referenz nur ein anderer Name für die Variable selbst ist und somit auch keine Adresse,
sondern die Variable selbst enthält.
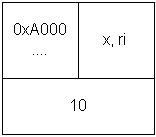
Die Variable hat eine Adresse und einen Wert, außerdem bekommt sie einen zweiten Namen, nämlich "ri", Referenz auf i.
Bsp. für Zeiger:
void Fkt3(int *zi);
Der Platz in den Funktionsklammern gehört zum Deklarationsraum, d.h. ebenso wie ganz oben unter den Include Befehlen
und in einer Funktion kann hier etwas deklariert werden. Das bedeutet zugleich, dass der Sternoperator hier nicht
der Dereferenzierung, sondern der Deklaration eines Zeigers dient.
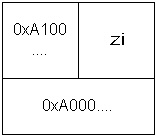
Der Zeiger zi hat selbst eine Adresse, die sich von der Adresse der Variablen x unterscheidet. Sein Inhalt ist aber
die Adresse der Variablen x. Um nun die 10 anzuzeigen, die in x steht, oder diese mit einer anderen Zahl zu
überschreiben, muss man zi dereferenzieren:
Lesezugriff: cout<<*zi;
Schreibzugriff: *zi = 35;
Hier muss man sich darüber im Klaren sein, dass fortan in der Variablen x selbst die 35 steht.
Dabei muss dem Zeiger zi natürlich zuvor die Adresse von x zugewiesen worden sein. Irgendwo muss also stehen:
zi = & x; In diesem Fall ist ampersand der Adressoperator.
Speicherverwaltung
Für gewöhnlich steht im Arbeitsspeicher eines Systems Adressraum zur Verfügung, der teils als STACK
und teils als HEAP realisiert wird. STACK ist die einfachere von beiden Formen. STACK ist ein FILO - Speicher,
was soviel wie "first in - last out" bedeutet. Man kann ihn mit einem Kellerschacht vergleichen, in den man nacheinander
Kartoffelsäcke wirft. Natürlich muss man dann den obersten Sack erst herausnehmen, bevor man an den zweitobersten kommt, usw.
Der Compiler entscheidet selbst, was auf den Stack und was auf den Heap kommt.
Der Stack ist durch seine FILO Arbeitsweise besonders gut geeignet für alles, was sequentiell abgearbeitet wird.
Dies sind z.B. ineinandergeschachtelte Funktionen, Entscheidungen oder Schleifen. Alles was im Stack weiter unten liegt,
hat eine längere Lebensdauer, als das, was unten liegt. So liegen z.B. globale Variablen ganz unten, denn sie
sind solange gültig, wie das Programm läuft. Man kann zwar stets lesend oder schreibend auf sie zugreifen,
wird sie aber trotzdem erst aus dem Stack nehmen müssen, d.h. vernichten, nachdem alle anderen Elemente des Stack
vernichtet wurden, sprich also: am Ende des Programms. Rekursive Funktionen - solche die sich selbst aufrufen
oder eine andere Funktion aufrufen, die sie selbst wieder aufrufen - sind typische Elemente für den Stack.
Der HEAP ist intern komplexer organisiert, als der Stack. Das ist auch nötig, weil er z.B. dynamische
Speicherverwaltung mit namenlosen Variablen oder Objekten ermöglicht. Alles was jederzeit gelöscht oder neu angelegt
werden kann, landet auf dem HEAP.
Um mit dynamischem Speicher zu arbeiten, gibt es die Schlüsselworte new und delete.
Mit new Datentyp weist man den Compiler an, für eine Variable des angegebenen Datentyps Speicherplatz zu
reservieren, ohne dass die Variable einen Namen erhält. Der Speicherplatz der Variablen wird dynamisch verwaltet,
d.h., man muss nicht vorher wissen, wieviele Variable dieses Typs man eigentlich anlegen wird.
Diese dynamische Speicherplatzverwaltung findet auf dem Heap statt, wo man mit delete ein Element löschen kann,
egal, wo es steht. Auf dem Stack wäre das nicht möglich.
Verkettete Listen
Um eine verkettete Liste mit namenlosen Objekten realisieren zu können, muss man sich zunächst einmal visuell
vor Augen führen, was eigentlich gemeint ist:

LANF ist ein Zeiger auf den Listenanfang. LiNf ist ein Zeiger auf den Listennachfolger, der in der
Klassendeklaration bereits enthalten ist und sich daher in jedem Objekt dieser Klasse befindet. Auch im
letzten Element der Kette ist LiNf enthalten, muss dort aber auf NULL zeigen. NULL ist keine numerische Null,
vielmehr bedeutet "NULL" soviel wie "überhaupt Nichts".
Beispielprogramm:
// Listenkette.cpp : Definiert den Einsprungpunkt für die Konsolenanwendung.
//
#include "StdAfx.h"
#include <string>
#include <iostream>
using namespace std;
class Mitarb
{
public: //Eigenschaften
int PersNr;
string Name;
Mitarb *ListNf;
Mitarb( ); //Methoden
Mitarb(int,string);
~Mitarb( );
void Ausgabe( );
};
Mitarb::Mitarb(int initPersNr, string initName) //überladener Konstruktor
{
PersNr=initPersNr;
Name=initName;
ListNf=NULL;
}
Mitarb::Mitarb( ) //Standard Konstruktor
{;}
void Mitarb::Ausgabe( )
{
cout<<"Mitarbeiter-Ausgabe: "<<PersNr<<" "<<Name<<" "<<ListNf<<endl;
}
Mitarb::~Mitarb( ){cout<<PersNr<<" "<<Name<<endl;} //Destruktor
int main( )
{
int ePersNr;
string eName;
char Antwort;
Mitarb *ListAnf, *Z1Mitarb;
ListAnf = new Mitarb(3, "Rosalie");
ListAnf->Ausgabe( );
cout<<"Neuen Mitarbeiter eingeben, j?"<<endl;
cin>>Antwort;
while(Antwort = = 'j')
{
cout<<"Personalnummer Name "<<endl;
cin>>ePersNr>>eName;
Z1Mitarb=new Mitarb(ePersNr, eName);
Z1Mitarb->Ausgabe( );
Z1Mitarb->ListNf=ListAnf;
ListAnf=Z1Mitarb;
cout<<"Neuen Mitarbeiter eingeben, j?"<<endl;
cin>>Antwort;
}
cout<<endl<<"***********Ausgabe der gesamten Liste***********"<<endl<<endl;
Z1Mitarb=ListAnf;
while(Z1Mitarb!=NULL)
{
Z1Mitarb->Ausgabe( );
Z1Mitarb=Z1Mitarb->ListNf;
}
cout<<endl<<endl;
for(Z1Mitarb=ListAnf; Z1Mitarb-> PersNr!=3; Z1Mitarb=Z1Mitarb-> ListNf)
{;}
cout<<"die drei hat: ";
Z1Mitarb-> Ausgabe( );
cout<<endl;
cout<<"es verabschiedet sich: Rosalie ";
delete Z1Mitarb;
cout<<endl<<" programmende "<< endl <<endl;
return 0;
}
Weiter zu Polymorphie und Vererbung